파이썬으로 파싱 후 select 함수 사용에서 궁금한 점
-
게시물 수정 , 삭제는 로그인 필요
아래와 같은 주소를 파싱하여 select 함수 사용했습니다.
import requests as rq
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://kind.krx.co.kr/disclosure/todaydisclosure.do?method=searchTodayDisclosureMain&marketType=0'
krx = rq.get(url)
krx_html = BeautifulSoup(krx.content, 'html.parser')
krx_title = krx_html.select('section.wrapper-contents > section.contents')
#html의 상위 코드에서부터 순서대로 입력해야 select 함수를 사용할 수 있다.
print(krx_title)
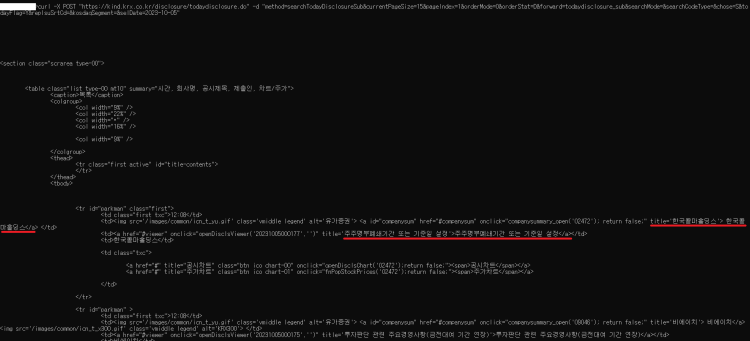
분명 사이트의 html 요소에는 아래 사진과 같이 article 태그에 꼬리를 무는 태그들이 많은데,

코드를 작동해 article 부분을 찾아보면
<article class="pcontents" id="main-contents">
</article>
이렇게만 나옵니다.
이거 저 url의 개발자가 크롤링 못하도록 막아놓은 것일까요?
+ 프로그램 관련 질문 하는 사이트 알고 계시면 몇개만 알려주세요.
감사합니다.
import requests as rq
from bs4 import BeautifulSoup
import pandas as pd
url = 'https://kind.krx.co.kr/disclosure/todaydisclosure.do?method=searchTodayDisclosureMain&marketType=0'
krx = rq.get(url)
krx_html = BeautifulSoup(krx.content, 'html.parser')
krx_title = krx_html.select('section.wrapper-contents > section.contents')
#html의 상위 코드에서부터 순서대로 입력해야 select 함수를 사용할 수 있다.
print(krx_title)
분명 사이트의 html 요소에는 아래 사진과 같이 article 태그에 꼬리를 무는 태그들이 많은데,
코드를 작동해 article 부분을 찾아보면
<article class="pcontents" id="main-contents">
</article>
이렇게만 나옵니다.
이거 저 url의 개발자가 크롤링 못하도록 막아놓은 것일까요?
+ 프로그램 관련 질문 하는 사이트 알고 계시면 몇개만 알려주세요.
감사합니다.
#파이썬으로 json 파싱