<#파이썬> 네이버뉴스 제목에서 원하는 텍스트만 크롤링 후 뉴스...
-
게시물 수정 , 삭제는 로그인 필요
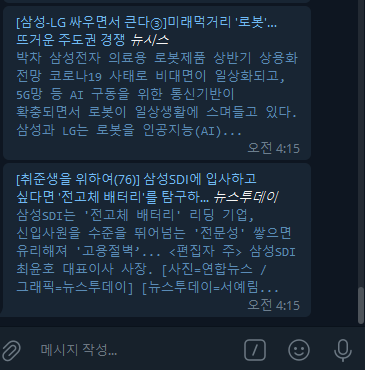
<#파이썬> 네이버뉴스 제목에서 원하는 텍스트만 크롤링 후 뉴스제목,url을 텔레그램 봇 전송을 하기 위해서 여러 고수님들이 공개해주신 코드를 가지고 공부했으나 미천한 실력으로 진행이 안되고 있습니다. 제발 도와주세요. 주식하는데 필요한 기사를 실시간 전송이 필요합니다.
붙임 코드 중 안되는 부분과 제가 필요한 부분을 말씀드리겠습니다.
1. 현재상황
search word(검색어)를 본문에서 검색하여 봇에 전송까지는 성공했지만,
가. 본문에서 검색어를 검색하기에 너무 광범위해지는 문제점 발생
나. 며칠 전 기사도 포함되어 검색되는 문제점 발생
다. 텔레그램봇으로 전송은 되나 제목이 아니라 링크가 전송되어 직관성이 떨어지는 문제점 발생
라. 검색어를 추가할 때 계속 코드변경을 수정해야 하는 문제점 발생
2. 해결을 위한 고민
가. 본문이 아니라 제목에 검색어가 포함된 기사만 크롤링
나. 실시간 대응을 위하여 1분(심지어 실시간) 이내의 기사만 전송
다. 텔레그램 봇으로 전송시 기사 제목을 전송(텔레그램 확인 시 url, 기사 앞부분 등 표시 및 클릭시 기사페이지로 이동
라. 텔레그램에서 검색어 추가 및 삭제기능 탑제
제 컴퓨터는 거의 24시간 켜져있다고 보시면 됩니다. 고수님들의 도움이 절실합니다~
<#파이썬> 네이버뉴스 제목에서 원하는 텍스트만 크롤링 후 뉴스제목,url을 텔레그램 봇 전송을 하기 위해서 여러 고수님들이 공개해주신 코드를 가지고 공부했으나 미천한 실력으로 진행이 안되고 있습니다. 제발 도와주세요. 주식하는데 필요한 기사를 실시간 전송이 필요합니다.
붙임 코드 중 안되는 부분과 제가 필요한 부분을 말씀드리겠습니다.
1. 현재상황
search word(검색어)를 본문에서 검색하여 봇에 전송까지는 성공했지만,
가. 본문에서 검색어를 검색하기에 너무 광범위해지는 문제점 발생
나. 며칠 전 기사도 포함되어 검색되는 문제점 발생
다. 텔레그램봇으로 전송은 되나 제목이 아니라 링크가 전송되어 직관성이 떨어지는 문제점 발생
라. 검색어를 추가할 때 계속 코드변경을 수정해야 하는 문제점 발생
2. 해결을 위한 고민
가. 본문이 아니라 제목에 검색어가 포함된 기사만 크롤링
나. 실시간 대응을 위하여 1분(심지어 실시간) 이내의 기사만 전송
다. 텔레그램 봇으로 전송시 기사 제목을 전송(텔레그램 확인 시 url, 기사 앞부분 등 표시 및 클릭시 기사페이지로 이동
라. 텔레그램에서 검색어 추가 및 삭제기능 탑제
제 컴퓨터는 거의 24시간 켜져있다고 보시면 됩니다. 고수님들의 도움이 절실합니다~